Linguagens de programação e bancos de dados
- Python com foco em análise de dados e Machine Learning
- Web scraping com Python
- SQL para extração de dados
- R para modelagem estatística
- Banco de dados SQLite, Postgres, MySQL
Aqui, pretendo te apresentar minhas habilidades para resolver problemas de negócios utilizando ferramentas e conceitos de Ciência de dados através de projetos.
Esses projetos foram desenvolvidos com dados públicos e com ferramentas open source conhecidas do mercado.
Além dos projetos, descrevo minhas habilidades, objetivos e experiências profissionais atual para que você possa me conhecer um pouco mais.
No fim da página há links para que você possa entrar em contato. Sinta-se à vontade!

Meu nome é Marcus Vinícius (Vinícius), tenho 33 anos e trabalho como agente comercial no Banco do Brasil.
Atualmente trabalho comercializando produtos bancários como créditos pessoa física e jurídica, seguridade, consórcio, investimentos, etc. para clientes da carteira do banco, de acordo com seu perfil.
Sou graduado em Análise e Desenvolvimento de Sistemas (término em Jan/2020) e pós-graduado em Estatística Aplicada (término em Dez/2021). Estudo Ciência de Dados desde 2019 através de vários cursos presentes na Data Science Academy, na Alura e Comunidade DS. Nesses cursos, aprendo a resolver problemas de negócio atráves dos conceitos fornecidos pela Ciência de dados, além do método cíclico de um projeto, desde a definição do problema até o deploy do modelo de Machine Learning.
Busco uma oportunidade de trabalhar profissionalmente como Cientista de Dados para auxiliar na melhoria nas tomadas de decisão de empresas através dos conhecimentos extraídos de dados.
Trabalhos executados em empresas como Estrela H Motos (revendas Honda) e UNIP (Universidade Paulista).

Utilizei algoritmos de classificação para melhor predizer se um paciente, de acordo com os dados de entrada, precisaria ser internado em UTI ou não em decorrência de COVID-19, utilizando validação cruzada e métricas para comparação entre as performances dos modelos. Executei análise exploratória e visualização para melhor entender os dados e tentar extrair conhecimento deles.
Nesse projeto foi feita uma análise exploratória mais detalhada para melhor entendimento dos dados, além de formulações de hipóteses a serem verificadas sobre o negócio. Usei modelos de regressão para fazer a predição, além de validação cruzada e comparação de métricas para avaliar o modelo com melhor performance.
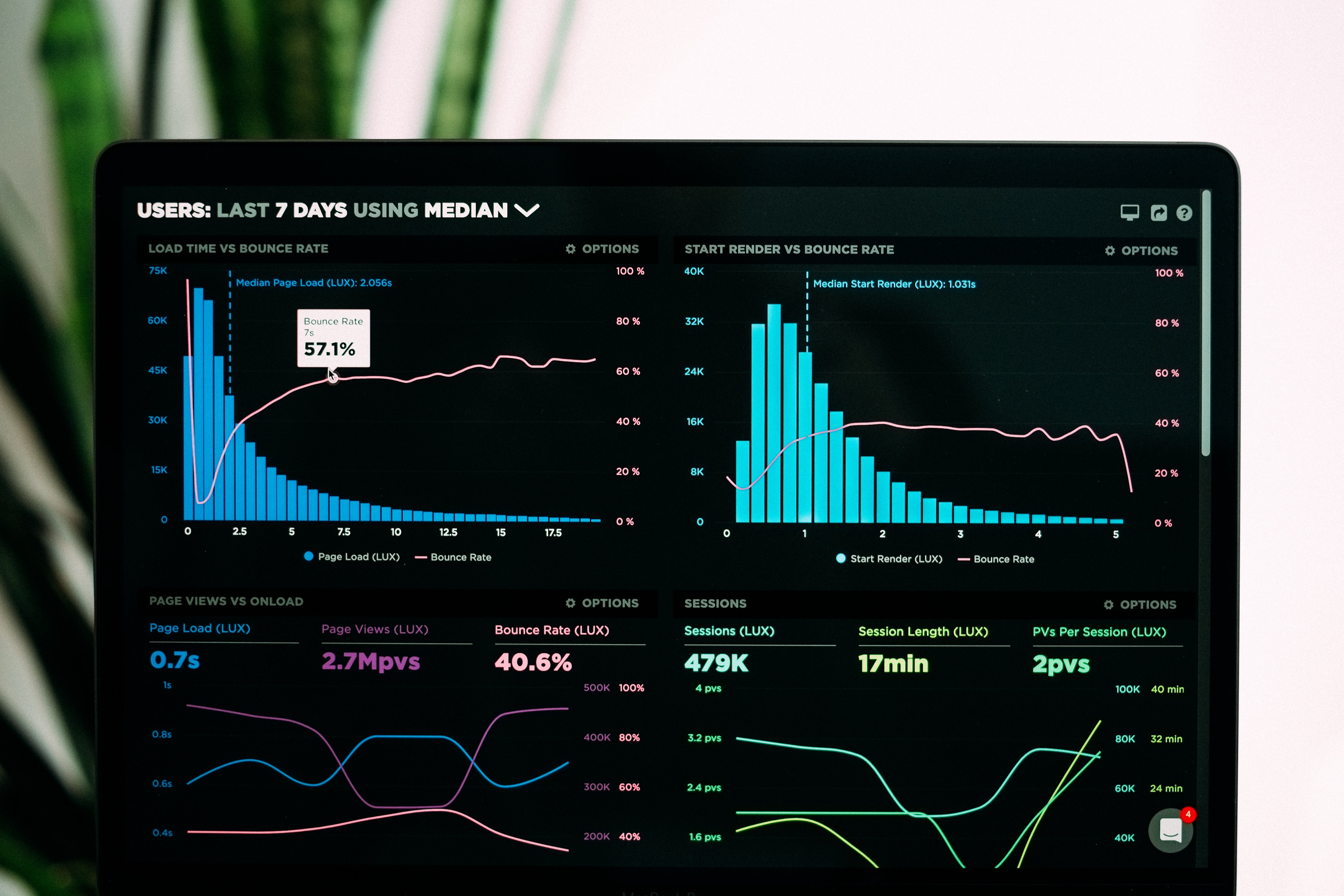
A análise será feita sobre os dados da Covid-19 no Brasil extraídos diretamente do site https://covid.saude.gov.br/, administrado pelo Ministério da saúde. Esses dados foram coletados em 14/01/2021. Com eles, foi feita uma pequena análise dos números de casos e de mortes (Brasil e alguns estados) e a predição de séries temporais de novos casos.

A base de dados estudada nesse módulo é do IBGE, chamada Pense (Pesquisa Nacional da Saúde do Escolar). Podemos entender, através dela, a relação entre saúde e educação e como o ambiente de vivência do estudante pode influenciar na qualidade de seu desenvolvimento escolar e vice-versa.